
LSP Software - Официальный дистрибьютор программного обеспечения SDL Trados - Совместное использование большого файла SDLXLIFF (без его разделения) часть 2
В предыдущей части блога мы узнали, как отделить модули от большого файла sdlxliff между несколькими переводчиками в SDL Trados Studio, а затем перенести частичные переводы в один файл, получив таким образом один переведенный документ в целом. Этот метод разделения большого файла основан на функции PerfectMatch , которая, однако, доступна только в Профессиональной версии. Что если у нас есть только внештатная версия? В этой части мы узнаем, как получить подобный эффект без использования функции PerfectMatch .
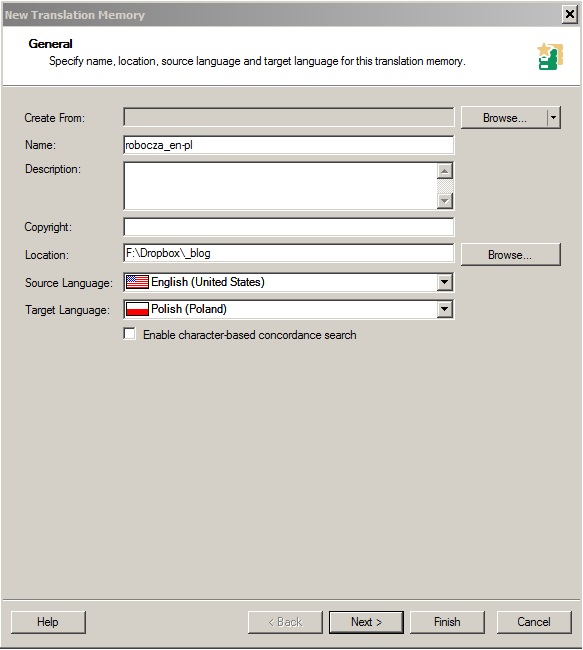
В начале мы создаем рабочий память переводов в нашем примере это работа memory_en-en:
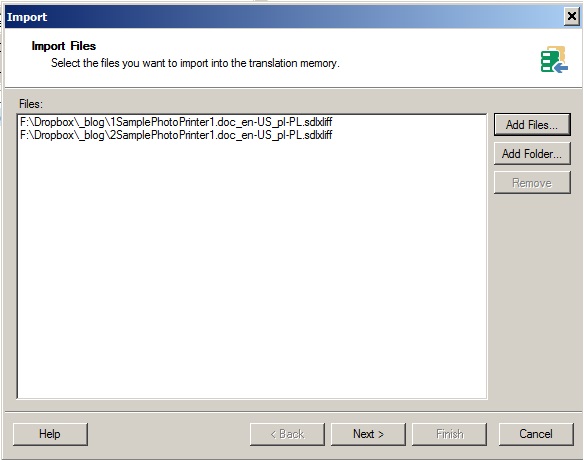
Затем мы импортируем в него все единицы из переведенных частичных файлов (файлы 1_ SamplePhotoPrinter.doc.sdlxliff и 2_ SamplePhotoPrinter.doc.sdlxliff - см. часть 1 ):
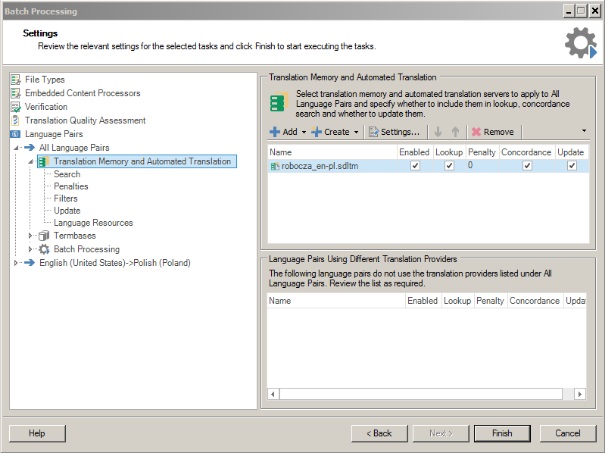
Теперь мы открываем наш оригинальный файл sdlxliff и выбираем представление Files . Щелкните правой кнопкой мыши имя файла и выберите « Пакетные задачи» и « Предварительный перевод файлов» . В окне « Пакетные задачи» нажмите кнопку « Далее» . В окне « Настройки» щелкните « Память переводов» и «Автоматический перевод» , а затем добавьте нашу рабочую память переводов.
Нажмите Готово и Закрыть . В окне « Вопрос» нажмите « Да» . Переведенный файл будет открыт в редакторе Studio.

Мы видим, что почти все модули имеют статус ContextMatch . Как мы помним, в методе, описанном в первой части, единицы файла результатов находились в состоянии PerfectMatch . Какая разница?
Чтобы обеспечить максимальную контекстную совместимость, PerfectMatch проверяет как предыдущий, так и следующий текстовый сегмент. Перевод текущего сегмента вставляется, если в документе, из которого происходит перевод, предыдущий и следующий сегменты идентичны тем, которые содержатся в текущем документе. Функция ContextMatch основана на информации, хранящейся в память переводов где информация о предыдущем сегменте хранится для данного сегмента. Вставленный из памяти переводов сегмента перевода, он получает статус ContextMatch , если предыдущий сегмент в документе, из которого перевод был вставлен в память перевода, такой же, как в текущем документе. Что касается первого сегмента в документе (когда нет предыдущего сегмента), принимается во внимание другая информация, например, что первый сегмент является заголовком документа.
В нашем примере документа сегмент № 11 имеет статус 100%. Это связано с тем, что первоначально переведенный сегмент был первым сегментом второго файла частичного перевода, поэтому предыдущий сегмент (№ 10) был пустым:

Чтобы быть уверенным, стоит проверить правильность сегментов со статусом 100% (они происходят в местах, где исходный файл разделен).
Описанные методы также можно использовать для «сохранения» поврежденного файла sdlxliff, из которого результирующий файл не может быть сгенерирован. Но об этом в следующем посте.