
Обратный инжиниринг алгоритм YouTube
[Примечание редактора: вы можете прочитать Обратный инжиниринг алгоритма YouTube: часть I Прямо здесь , Вам не нужно читать это перед прочтением части II, но вы должны проверить это в какой-то момент. Это отлично.]
Команда исследователей Google представила газета в Бостоне, штат Массачусетс, 18 сентября 2016 года титулованный Глубокие нейронные сети для рекомендаций YouTube на 10-й ежегодной конференции Ассоциации по вычислительной технике по рекомендательным системам (или, как называют крутые ребята, ACM RecSys '16).
Эта статья была написана Пол Ковингтон (в настоящее время старший инженер-программист в Google), Джей Адамс (в настоящее время инженер-программист в Google) и Эмбре Саргин (в настоящее время старший инженер-программист в Google), чтобы показать другим инженерам, как YouTube использует Глубокие Нейронные Сети за Машинное обучение , Это связано с некоторыми довольно техническими, высокоуровневыми вещами, но в конечном итоге эта статья иллюстрирует, как работает весь алгоритм рекомендаций YouTube (!!!). Это дает внимательному и осторожному читателю представление о том, как на самом деле функционируют функции YouTube «Просмотр», «Предлагаемые видео» и «Рекомендуемые видео».
Технический документ по алгоритму YouTube для чайников
Хотя авторы не обязательно преследовали цель, мы считаем, что документ Deep Neural может быть прочитан и интерпретирован издателями видео YouTube. Ниже показано, как мы (и когда я говорю «мы», я имею в виду меня и мою команду в моей новой блестящей компании Little Monster Media Co. ) интерпретировать эту статью как видеоиздатель.
В предыдущем посте я соавтором здесь на Tubefilter, Обратный инжиниринг алгоритм YouTube мы сосредоточились на основной драйвер алгоритма Watch Time , Мы просмотрели данные наших видео на нашем канале, чтобы понять, как работает алгоритм YouTube. Однако одним из факторов, ограничивающих этот подход, является то, что он исходит с точки зрения издателя видео. В попытке получить представление об алгоритме YouTube мы задали себе вопрос, а затем ответили на вопрос: «Почему наши видео успешны?» Мы старались изо всех сил использовать имеющуюся у нас информацию, но наша первоначальная предпосылка не была идеальной. И хотя я полностью поддерживаю наши выводы, проблема с нашим предыдущим подходом в основном состоит из двух частей:
- Просмотр отдельного набора метрик канала означает, что в наших данных есть огромная слепая зона, поскольку у нас нет доступа к конкурентным метрикам, метрикам сеансов и рейтингам кликов.
- Алгоритм YouTube придает очень мало значения метрикам, основанным на видео издателях. Это гораздо больше касается аудитории и индивидуальных показателей на основе видео. Или, с точки зрения непрофессионалов, алгоритм на самом деле не заботится о видео, которые вы публикуете, но он очень заботится о видео, которые вы (и все остальные) смотрите.
Но в то время, когда мы писали нашу оригинальную статью, из YouTube или Google не было выпущено ничего, что могло бы пролить свет на алгоритм осмысленно. Опять же, мы сделали то, что могли, с тем, что имели. К счастью для нас, статья, недавно выпущенная Google, дает нам представление о том, как работает алгоритм и некоторые из его наиболее важных показателей. Надеемся, что это позволит нам ответить на более острый вопрос: «Почему видео успешно?»
Смотреть в глубокую обучающую пропасть
Большой вывод из введения в статью состоит в том, что YouTube использует Deep Learning для усиления своего алгоритма. Это не совсем новости, но это подтверждение того, во что многие верили в течение некоторого времени. Авторы раскрывают в своем вступлении:
В этой статье мы сконцентрируемся на огромном влиянии, которое глубокое обучение недавно оказало на систему рекомендаций к видео YouTube. В сочетании с другими областями продуктов в Google, YouTube претерпел фундаментальный сдвиг парадигмы в сторону использования глубокого обучения в качестве универсального решения для почти все проблемы с обучением.
Это означает, что с возрастающей вероятностью не будет никаких людей, которые на самом деле делают алгоритмические настройки, измеряют эти настройки, а затем внедряют эти настройки на крупнейшем в мире сайте обмена видео. Алгоритм принимает данные в режиме реального времени, ранжирует видео, а затем выдает рекомендации на основе этих рейтингов. Поэтому, когда YouTube заявляет, что не может сказать, почему алгоритм делает то, что он делает, это, вероятно, означает буквально.
Две нейронные сети
Статья начинается с изложением базовой структуры алгоритма. Это первая иллюстрация автора:
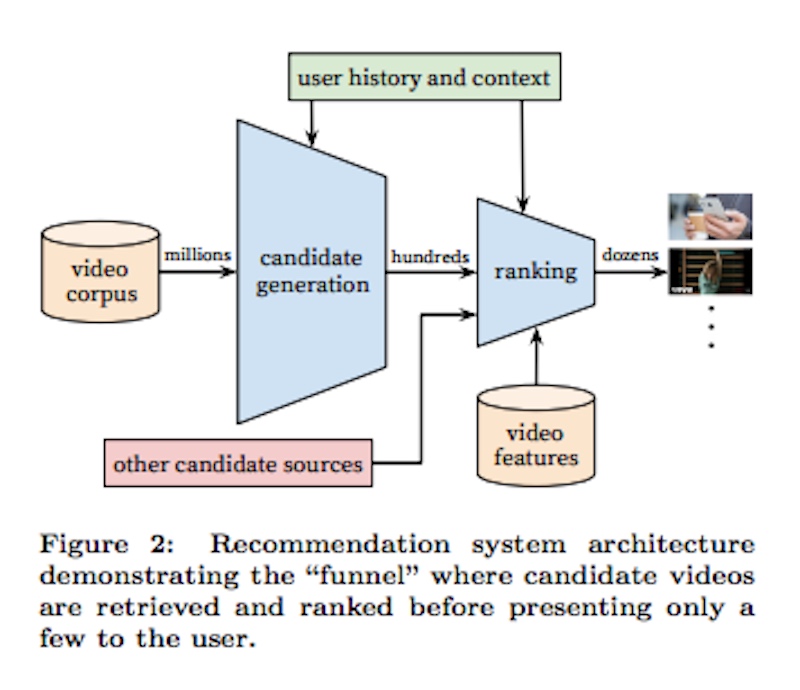
По сути, есть два больших фильтра с разными входами. Авторы пишут:
Система состоит из двух нейронных сетей: одна для генерации кандидатов и одна для ранжирования.
Эти два фильтра и их входы по существу определяют каждое видео, которое зритель видит в функциях «Предложенные видео», «Рекомендовать видео» и «Обзор» YouTube.
Первый фильтр - Генерация Кандидатов . В документе говорится, что это определяется «историей активности пользователя на YouTube», которая может быть прочитана как история просмотра пользователя и время просмотра. Генерация кандидатов также определяется тем, что смотрели другие похожие зрители, что авторы называют совместной фильтрацией . Этот алгоритм решает, кто является аналогичным зрителем, с помощью «грубых функций, таких как идентификаторы видеонаблюдений, маркеры поисковых запросов и демография».
Чтобы свести это к минимуму, чтобы видео стало одним из «сотен» видео, которое проходит через первый фильтр Candidate Generation, это видео должно быть связано с историей просмотра пользователя, а также должно быть видео, похожее на зрителей. смотрели.
Второй фильтр - фильтр ранжирования . В статье подробно рассматривается Фильтр ранжирования и приводятся некоторые значимые факторы, из которых он состоит. Фильтр ранжирования, пишут авторы, ранжирует видео по:
… Присвоение баллов каждому видео в соответствии с желаемой целевой функцией с использованием богатого набора функций, описывающих видео и пользователя. Видео с наивысшей оценкой представлены пользователю, ранжированные по его оценке.
Поскольку Watch Time является главной целью YouTube для зрителей, мы должны предположить, что это «желаемая целевая функция». Таким образом, оценка основана на том, насколько хорошо видео, учитывая различные пользовательские данные, будет генерировать время просмотра. Но, к сожалению, все не так просто. Авторы показывают, что в расчет алгоритма входит гораздо больше.
Мы обычно используем сотни функций в наших рейтинговых моделях.
Как алгоритм ранжирует видео, где математика становится действительно сложной. В документе также не указано ни о сотне факторов, рассматриваемых в моделях ранжирования, ни о том, как эти факторы взвешиваются. Тем не менее, он ссылается на три элемента, упомянутых в фильтре «Генерация кандидатов» (это «История наблюдения», «История поиска» и «Демографическая информация») и некоторые другие, включая «свежесть»:
Многочасовые видео загружаются каждую секунду на YouTube. Рекомендация этого недавно загруженного («свежего») контента чрезвычайно важна для YouTube как продукта. Мы постоянно отмечаем, что пользователи предпочитают свежий контент, хотя и не в ущерб актуальности.
Бумага отмечает, что один интересный недостаток заключается в том, что на алгоритм необязательно влияет последнее, что вы смотрели (если у вас очень ограниченная история). Авторы пишут:
Мы «откатываем» историю пользователя, выбирая случайные часы и действуя только на те действия, которые пользователь предпринял перед просмотром ярлыков.
В следующем разделе статьи они обсуждают рейтинг кликов (или CTR) на видео-впечатления (так называемые миниатюры и заголовки видео) , Говорится:
Например, пользователь может смотреть данное видео с высокой вероятностью в целом, но вряд ли нажмет на конкретное впечатление от домашней страницы из-за выбора миниатюрного изображения…. Наша конечная цель ранжирования постоянно настраивается на основе результатов живого A / B-тестирования, но как правило, простая функция ожидаемого времени просмотра за показ.
Это не удивительно, рейтинг кликов здесь называется. Для того, чтобы сгенерировать время просмотра, видео должно заставить кого-то смотреть его в первую очередь, и самый верный способ сделать это - с большим миниатюром и отличным названием. Это дает доверие к претензии многих создателей этот рейтинг кликов чрезвычайно важен для рейтинга видео в алгоритме.
YouTube знает, что CTR можно использовать поэтому они обеспечивают противовес. Этот документ подтверждает это, когда в нем говорится следующее:
Ранжирование по рейтингу кликов часто продвигает вводящие в заблуждение видеоролики, которые пользователь не завершает («приманка для кликов»), тогда как время просмотра лучше фиксирует вовлеченность [13, 25].
Хотя это может показаться обнадеживающим, авторы продолжают писать:
Если пользователю недавно было рекомендовано видео, но он не смотрел его, модель естественным образом продемонстрирует это впечатление при загрузке следующей страницы.
Эти утверждения поддерживают идею о том, что если зрители не нажимают на определенное видео, алгоритм прекратит показ этого видео аналогичным зрителям. В этой статье есть доказательства того, что это происходит и на канале. В нем говорится (с моим дополнительным акцентом):
Мы видим, что наиболее важными сигналами являются те, которые описывают предыдущее взаимодействие пользователя с самим элементом и другими подобными элементами… В качестве примера рассмотрим прошлую историю пользователя с каналом, который загрузил оцениваемое видео - сколько видео просмотрел пользователь с этого канала? Когда в последний раз пользователь смотрел видео на эту тему? Эти непрерывные функции, описывающие действия пользователя в отношении связанных элементов , особенно мощны …
Кроме того, в документе отмечается, что при обучении алгоритму учитываются все сеансы просмотра YouTube, включая те, которые не являются частью рекомендаций алгоритма:
Учебные примеры генерируются из всех просмотров YouTube (даже встроенных на других сайтах), а не просто из рекомендаций, которые мы производим. В противном случае было бы очень трудно обнаружить новый контент, и рекомендатель был бы чрезмерно склонен к эксплуатации. Если пользователи обнаруживают видео с помощью средств, отличных от наших рекомендаций, мы хотим иметь возможность быстро распространять это открытие среди других с помощью совместной фильтрации.
В конечном счете, все это возвращается к Watch Time для алгоритма. Как мы видели в начале статьи, когда в ней говорилось, что алгоритм предназначен для достижения « желаемой целевой функции », авторы заключают: « Наша цель - прогнозировать ожидаемое время наблюдения », а «Наша конечная цель ранжирования постоянно настраивается основаны на результатах живого A / B-тестирования, но, как правило, представляют собой простую функцию ожидаемого времени просмотра на показ. »
Это еще раз подтверждает, что Watch Time - это то, для чего все факторы, входящие в алгоритм, предназначены для создания и продления. Алгоритм взвешен, чтобы стимулировать наибольшее количество времени на месте и более длительные сеансы просмотра.
Напомним
Это много, чтобы принять. Давайте быстро рассмотрим.
- YouTube использует три основных фактора просмотра для выбора видео для продвижения. Эти входные данные - история просмотра, история поиска и демографическая информация.
- Существует два фильтра, через которые видео должно проходить, чтобы продвигаться с помощью функций просмотра, рекомендуемых видео и рекомендуемых видео на YouTube:
- Фильтр генерации кандидатов
- Рейтинговый фильтр
- Фильтр ранжирования использует входные данные зрителя, а также другие факторы, такие как «Свежесть» и рейтинг кликов.
- Рекламный алгоритм предназначен для постоянного увеличения времени просмотра на месте за счет непрерывного A / B-тестирования видео и последующей передачи этих данных обратно в нейронные сети, чтобы YouTube мог продвигать видео, что приводит к увеличению продолжительности сеансов просмотра.
Все еще в замешательстве? Вот пример.
Чтобы объяснить, как это работает, давайте рассмотрим пример системы в действии.
Джош действительно любит YouTube. У него есть аккаунт на YouTube и все! Он уже вошел в YouTube, когда он посещает сайт однажды. И когда он это делает, YouTube назначает три «токена» для сеансов просмотра Джошем YouTube. Эти три жетона даются Джошу за кулисами. Он даже не знает о них! Это его История часов, История поиска и Демографическая информация.
Теперь в игру вступает фильтр «Генерация кандидатов». YouTube принимает значение этих «токенов» и объединяет его с историей просмотра зрителей, которые любят смотреть то же самое Джош любит смотреть , Остались сотни видео, которые Джош может заинтересовать, отфильтрованные из миллионов и миллионов видео на YouTube.
Далее, эти сотни видео ранжируются на основе их соответствия Джошу. Алгоритм задает и отвечает на следующие вопросы за доли секунды: Насколько вероятно, что Джош будет смотреть видео? Насколько вероятно, что видео приведет к тому, что Джош проведет много времени на YouTube? Насколько свежо видео? Как Джош недавно общался с YouTube? Плюс сотни других вопросов!
Лучшее видео затем передается Джошу в функциях просмотра, рекомендуемого и рекомендуемого видео на YouTube. И решение Джоша о том, что смотреть (а что нет) отправляется обратно в нейронную сеть, чтобы алгоритм мог использовать эти данные для будущих зрителей. Продолжается показ видео, на которые нажимают, и которые пользователи долго смотрят. Те, кто не получают клики, могут не пройти через фильтр Генерация кандидатов при следующем посещении сайта Джошем (или зрителем вроде Джоша).
Заключение
Глубокие нейронные сети для рекомендаций YouTube это увлекательное чтение. Это первый настоящий проблеск в алгоритме, непосредственно из источника (!!!), который мы видели за очень долгое время. Я надеюсь, что мы продолжим видеть больше подобных статей, чтобы издатели могли лучше выбирать, какой контент они создают для платформы. И в конечном итоге именно поэтому я и пишу эти блоги. Создание контента, подходящего для платформы, означает, что создатели будут генерировать больше просмотров и, следовательно, больший доход, что в конечном итоге означает, что мы сможем создавать больше и улучшать программирование и предоставлять больше развлечений для миллиардов зрителей, которые каждый год затрачивают значительное время просмотра на YouTube.
 Мэтт Джилен является основателем и генеральным директором Little Monster Media Co ., видеоагентство, специализирующееся на развитии аудитории на YouTube и Facebook. Основанный летом 2016 года Little Monster уже помог десяткам клиентов, больших и маленьких, расширить свою аудиторию. Раньше Мэтт был вице-президентом по программированию и развитию аудитории во Frederator Networks, где он руководил созданием аудитории для Cartoon Hangover, Channel Frederator и Channel Frederator Network.
Мэтт Джилен является основателем и генеральным директором Little Monster Media Co ., видеоагентство, специализирующееся на развитии аудитории на YouTube и Facebook. Основанный летом 2016 года Little Monster уже помог десяткам клиентов, больших и маленьких, расширить свою аудиторию. Раньше Мэтт был вице-президентом по программированию и развитию аудитории во Frederator Networks, где он руководил созданием аудитории для Cartoon Hangover, Channel Frederator и Channel Frederator Network.
И в личном плагине, Мэтт погрузится во многое из этого и многое другое на его Презентации VidCon в этом году в Амстердаме, Анахайме и Австралии , Черт побери, что эти новые результаты означают для издателей и, что еще важнее, как издатели могут извлечь выгоду из информации, представленной в этом документе. Он рад видеть тебя там ,
Вы можете прочитать больше статей Мэтта на Tubefilter Вот и следуйте за Мэттом щебет ,
Все еще в замешательстве?
Алгоритм задает и отвечает на следующие вопросы за доли секунды: Насколько вероятно, что Джош будет смотреть видео?
Насколько вероятно, что видео приведет к тому, что Джош проведет много времени на YouTube?
Насколько свежо видео?
Как Джош недавно общался с YouTube?